Improve performance with cache prefetching
CPU puts recently used/often used data into small, very fast memory called cache. Understanding the basics of how cache works can lead to big performance improvements. The whole trick is to make the most of the data that already is in cache.
Cache basics
When a program needs to load some data, it looks for it first in the internal memory, which is the fastest — processor registers and cache. Cache is organized as hierarchy of cache levels:
- L1 is the fastest and the smallest level of cache, usually about few kilobytes (often 16-32kB). Hit latency : ~4 cycles,
- L2 is bigger (often 256kB-4MB), but slower. Hit latency: ~10 cycles,
- L3 is optional. Bigger and slower than L2. Hit latency: ~40 cycles.
The reference to main memory can be around 200 times slower than the reference to L1. Hit latency are example values for Core i7 Xeon 5500 Series [source].
On Linux it’s possible to check the cache size with the command lscpu. My CPU’s cache is following:
L1d cache: 32K
L1i cache: 32K
L2 cache: 256K
L3 cache: 3072KCache hierarchy
Program starts to look for the data in the fastest cache level (L1) first and if data is not found there it goes further to L2 and L3. If data is still not found, it reads the data from main memory (RAM). The slowest and the biggest memory is of course disc — it can store almost unlimited amount of data, but the disc seek can be around 100,000 times slower than reference to RAM. Figure below presents the memory size and speed dependency.
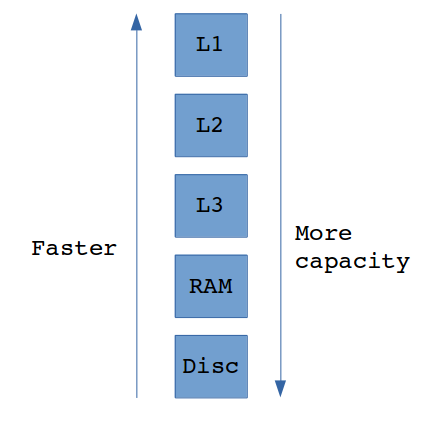
Memory size and reading speed dependency
Prefetching
When the needed data was not found in cache and was loaded from main memory, the CPU makes something to ensure that next operations on this data will be faster — it stores just fetched data into cache. Things that were in cache before can be erased to make room in cache for these new data.
But CPU in fact stores not only demanded data into cache. It also loads neighbouring (following) data in cache because it’s very likely that these data will be requested soon. Operation of reading more data than requested is called prefetching. If such prefetched data is in fact requested in the nearest future, it can be loaded with cache hit latency instead of expensive main memory reference.
Performance test
I made an experiment to check how much these cache things can improve. I implemented two almost identical functions, which sum all elements in the 2D array. The only difference is the traverse direction — first function sumArrayRowByRow reference to elements reading array row by row, second one — sumArrayColumnByColumn— column by column. If we consider the memory layout of 2D array, it’s obvious that only the first function references to array elements respecting their sequential order in memory.
quint64 sumArrayRowByRow()
{
quint64 sum = 0;
for (size_t i = 0; i < HEIGHT; i++)
{
for (size_t j = 0; j < WIDTH; j++)
{
sum += array[i][j];
}
}
return sum;
}quint64 sumArrayColumnByColumn()
{
quint64 sum = 0;
for (size_t i = 0; i < HEIGHT; i++)
{
for (size_t j = 0; j < WIDTH; j++)
{
sum += array[j][i];
}
}
return sum;
}The test was run for various sizes of square array of quint8: 32x32, 64x64, 128x128, 512x512, 1024x1024, 2048x2048 and 4096x4096.
The experiment showed no big differences for small-sized arrays. The theoretically better function, sumArrayRowByRow was only about 1% faster than sumArrayColumnByColumn for arrays of dimension 32x32, 64x64 and 128x128. The reason of that can be easily spotted. The total size of the biggest mentioned array is 128*128 bytes, which is about 16kB. It’s half the size of my L1d cache, so it’s possible that the whole array was loaded to cache.
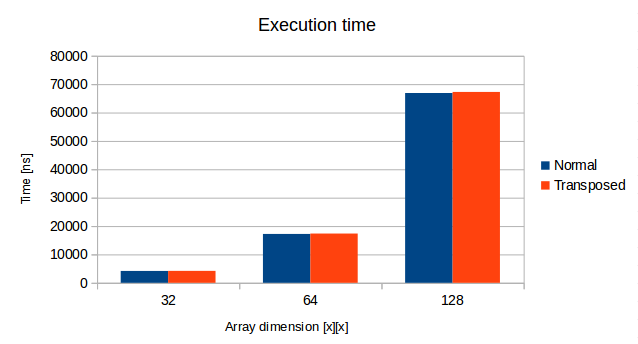
Cache influence on performance small array
The situation changes dramatically when the array size increases. The bigger the array was, the bigger advantage the “memory-ordered” function took. Operations on the biggest array 4096x4096 was more than 3 times slower with the sumArrayColumnByColumn function! This whole array takes ~16MB so there is no way to fit it whole into cache. Here prefetching made a big difference.
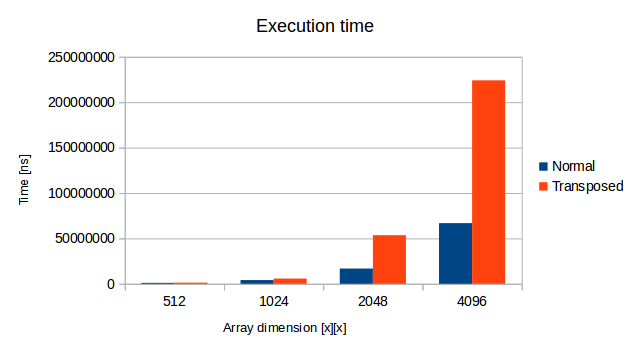
Cache influence on performance big array
Summary
Reference to elements in order of their memory placement. Traverse arrays in row-by-row manner, operate on the struct members in the order of their declaration and so on. Such approach may result in performance improvements.
I recommend this awesome article about cache: Gallery of processor cache effects .